Posted on October 3, 2016
By John Jones
Journal articles
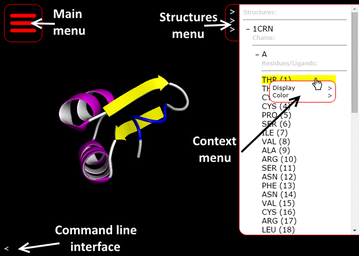
To encourage a move to allow mobile devices to better take advantage of molecular viewing techniques without having to create an application for every OS and environment, why not take advantage of more powerful GPU hardware accelleration in mobile devices? This is the train of thought Bekker
et al. take with their open-source, browser-based molecular viewing software Molmil, used extensively on the Protein Data Bank Japan project. Adding in support for highly detailed polygon models, realistic shaders, easy loading and saving of files, and a command-line interface, the group touts Molil as a strong option for the mobile environment. This 2016 paper further describes the software and its implementation.
Posted on September 26, 2016
By John Jones
Journal articles

No doubt, the traditional paper laboratory notebook isn't quite enough in many of today's modern labs. The research and fabrication labs of the National Institute of Standards and Technology (NIST) are no exception. This late 2015 paper published in the
Journal of Research of NIST expands upon the changing technological needs for a better and improved laboratory notebook, even beyond the largely software-focused electronic laboratory notebook (ELN). Gates
et al. discuss how they added the hardware component with their push for a “smart” electronic laboratory notebook (SELN) that is portable, intuitive, collaborative, and usable on tablet-based hardware in a cleanroom. They conclude their SELN "provides a comfortable portability and connectivity crucial to its role, and could actually also serve as a desktop replacement for many who do not require extremely powerful computing resources."
Posted on September 20, 2016
By John Jones
Journal articles

In this late 2015 review and background article, Goldberg
et al. provide the details of discussions held during meetings leading up to a February 2016 colloquium hosted by the American Academy of Microbiology on the
Applications of Clinical Microbial Next-Generation Sequencing. The details of these meetings reveal the state of next-generation sequencing, its clinical applications, and the regulatory, financial, and research barriers that exist in NGS' further expansion in clinical settings. They conclude that "[t]he rapid evolution of NGS challenges both the regulatory framework and the development of laboratory standards and will require additional funding and incentives to drive tangible improvements and progress" to realize "the potential benefit that NGS has for patients and their families."
Posted on September 12, 2016
By John Jones
Journal articles

Aronson
et al. of Partners HealthCare and their Laboratory for Molecular Medicine (LMM) experienced first-hand the process of developing infrastructure for the germline genetic testing process. In this 2016 paper published in
Journal of Personalized Medicine, the group shares its experiences of that process, from designating necessary support infrastructure (including a self-developed tool called GeneInsight Clinic) to its integration with other systems such as electronic health records, case management system, and laboratory information systems. They close by stating "a need for an application that interfaces with the range of systems" in the genetic testing environment and that "[s]uch a system could provide the basis for enhanced clinical decision support infrastructure."
Posted on September 6, 2016
By John Jones
Journal articles

"Defining and organizing the set of metadata that is relevant, informative and applicable to diverse experimental techniques is challenging," the team of Hong
et al. state in the introduction of this 2016 paper published in
Database. But the team, motivated by the Encyclopedia of DNA Elements (ENCODE) project and its offshoots, explain and demonstrate their metadata standard and its viability across many types of genomic assays and projects. The group believes that the standard's flexibility and ability to allow for transparent and reproducible experimental data offer much potential. "[A]long with its organizing principles and key features for implementation," they conclude, "[it] could be widely adopted as an open LIMS system."
Posted on August 30, 2016
By John Jones
Journal articles
This 2016 paper by Bianchi
et al., published in
Frontiers in Genetics, takes a closer look at the major issues concerning next-generations sequencing (NGS) technology. The group raises five main concerns than an NGS research group should be aware of before approaching NGS technologies and briefly states positives and negatives to the most current popular tools. The group concludes "[a]lthough larger groups with enough computational members may prefer to develop and maintain their own tailored frameworks, smaller laboratories would save resources and improve their results by adopting solutions developed by third parties," including open-source and cloud-based tools.
Posted on August 24, 2016
By John Jones
Journal articles

Most researchers in the life sciences know now of the concept of "big data" and the push to better organize and mine the data that comes out of biological research. However, the techniques used to mine promising and interesting information from accumulating biological datasets are still developing. In this 2016 paper published in
Bioinformatics and Biology Insights, Naulaerts
et al. look at three specific software tools for mining and presenting useful biological data from complex datasets. They conclude that while the Apriori and arules software tools have their benefits and drawbacks, "MIME showed its value when subsequent mining steps were required" and is inherently easy-to-use.
Posted on August 15, 2016
By John Jones
Journal articles

In this 2016 paper published in
Journal of Pathology Informatics, Cervin
et al. look at the state of pathology reporting, in particular that of structured or synoptic reporting. The group write about their prototype system that "sees reporting as an activity interleaved with image review rather than a separate final step," one that has "an interface to collect, sort, and display findings for the most common reporting needs, such as tumor size, grading, and scoring." They conclude that their synoptic reporting approach to pathology + imaging can provide a level of simplification to improve pathologists' time to report as well ability to communicate with the referring physician.
Posted on August 8, 2016
By John Jones
Journal articles
While big data is a popular topic these days, the quality of that data is at times overlooked. This 2015 paper published in
Data Science Journal attempts to address that importance and lay out a framework for big data quality assessment. After conducting a literature review on the topic, Cai and Zhu analyzed the challenges associated with ensuring quality of big data. "Poor data quality will lead to low data utilization efficiency and even bring serious decision-making mistakes," they conclude, presenting "a dynamic big data quality assessment process with a feedback mechanism, which has laid a good foundation for further study of the assessment model."
Posted on August 1, 2016
By John Jones
Journal articles
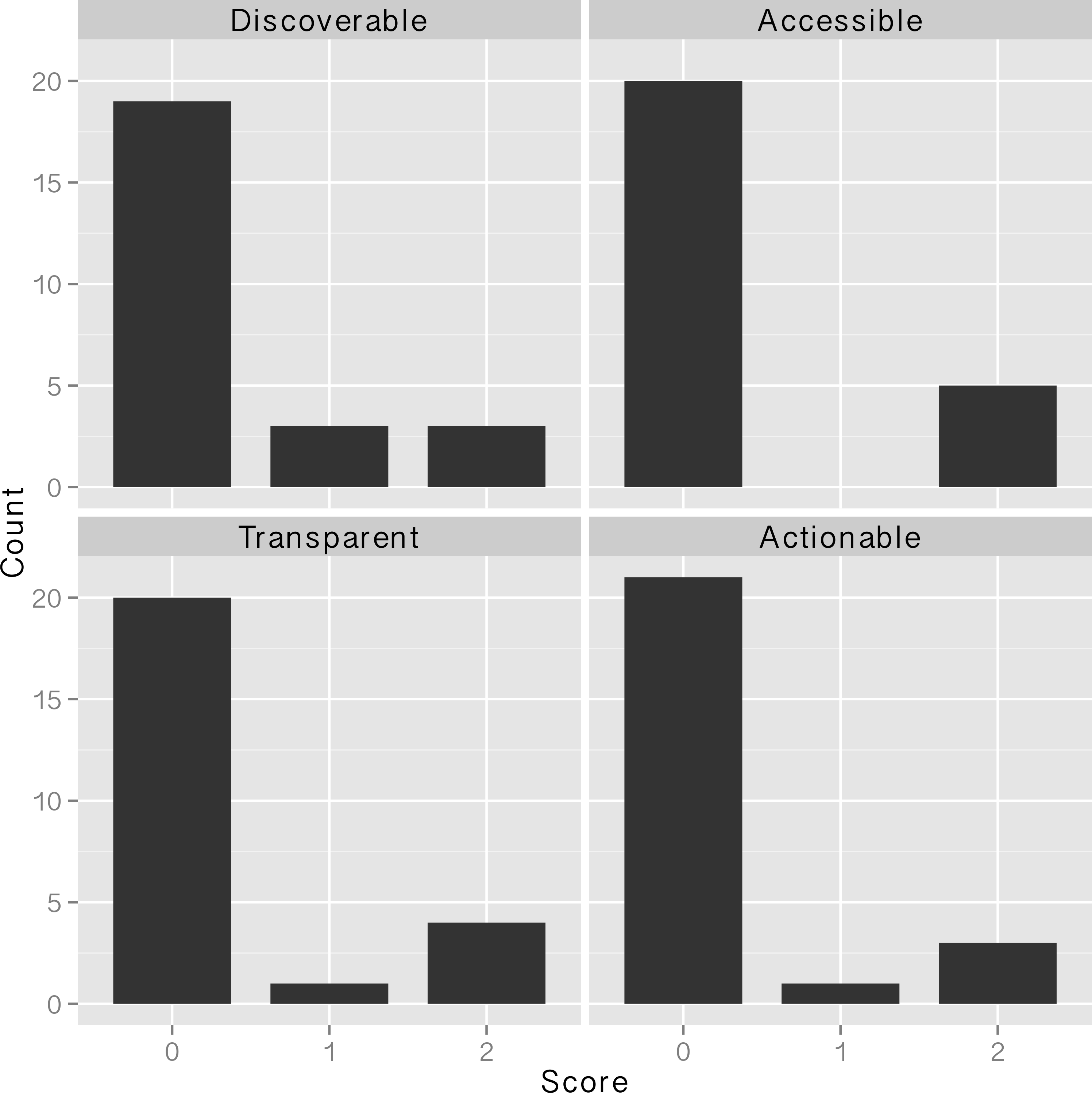
In this 2016 article published in
PLOS ONE, Van Tuyl and Whitmire take a close look at what "data sharing" means and what data sharing practices researchers have been using since the National Science Foundation's data management plan (DMP) requirements went into effect in 2011. Making federally-funded research "data functional for reuse, validation, meta-analysis, and replication of research" should be priority, they argue; however, they conclude not enough is being done in general. The researchers close by making "simple recommendations to data producers, publishers, repositories, and funding agencies that [they] believe will support more effective data sharing."
Posted on July 25, 2016
By John Jones
Journal articles
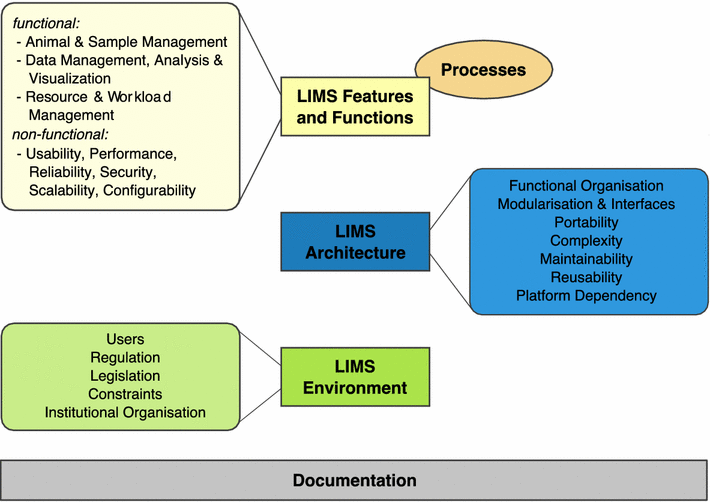
Clinical researchers conducting mouse studies at seven different facilities around the world shared their experiences using a laboratory information management system (LIMS) in order "to facilitate or even enable mouse and data management" better in their facilities. This 2015 paper by Maier
et al. examines those discussions and final findings in a "review" format, concluding "the unique LIMS environment in a particular facility strongly influences strategic LIMS decisions and LIMS development" though "there is no universal LIMS for the mouse research domain that fits all requirements."
Posted on July 19, 2016
By John Jones
Journal articles
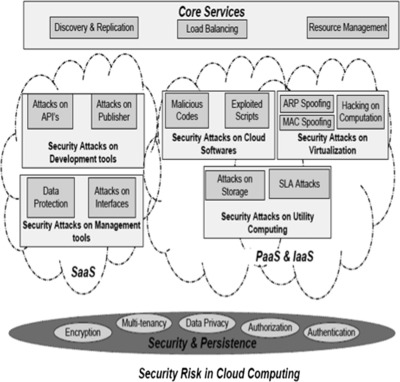
In this 2016 article in
Applied Computing and Informatics, Hussain
et al. take a closer look at the types of security attacks specific to cloud-based offerings and proposes a new multi-level classification model to clarify them, with an end goal "to determine the risk level and type of security required for each service at different cloud layers for a cloud consumer and cloud provider."
Posted on July 12, 2016
By John Jones
Journal articles

Published in the
Journal of eScience Librarianship, this 2016 article by Norton
et al. looks at the topic of "big data" management in clinical and translational research from the university and library standpoint. As academic libraries are a major component of such research, Norton
et al. reached out to the various medical colleges at the University of Florida and sought to clarify researcher needs. The group concludes that its research has led to "addressing common campus-wide concerns through data management training, collaboration with campus IT infrastructure and research units, and creating a Data Management Librarian position" to improve the library system's role with data management for clinical researchers.
Posted on July 6, 2016
By John Jones
Journal articles
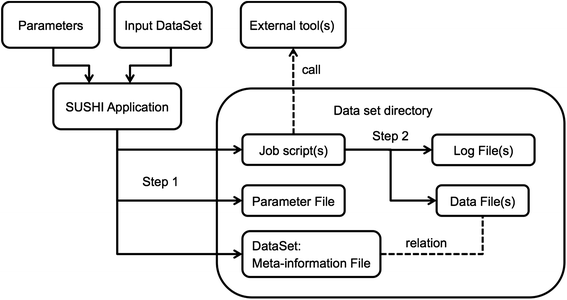
Many next-generation sequencing (NGS) data analysis frameworks exist, from Galaxy to bpipe. However, Hatakeyama
et al. at the University of Zürich noted a distinct lack of a framework that 1. offers both web-based and scripting options and 2. "puts an emphasis on having a human-readable and portable file-based representation of the meta-information and associated data." In response, the researchers created SUSHI (Support Users for SHell-script Integration). They conclude that "[i]n one solution, SUSHI provides at the same time fully documented, high level NGS analysis tools to biologists and an easy to administer, reproducible approach for large and complicated NGS data to bioinformaticians."
Posted on June 30, 2016
By John Jones
Journal articles

This 2014 paper by Ed Baker of London's Natural History Museum outlines a methodology for combining open-source software such as Drupal with open hardware like Arduino to create a real-time environmental monitoring station that is low-power and low-cost. Baker outlines step by step his approach (he calls it a "how to guide") to creating an open-source environmental data logger that incorporates a digital temperature and humidity sensor. Though he offers no formal conclusions, Baker states: "It is hoped that the publication of this device will encourage biodiversity scientists to collaborate outside of their discipline, whether it be with citizen engineers or professional academics."
Posted on June 21, 2016
By John Jones
Journal articles
Evaluating health information systems/technology is no easy task. Eivazzadeh
et al. recognize that, as well as the fact that developing evaluation frameworks presents its own set of challenges. Having looked at several different models, the researchers wished to develop their own evaluation method, one that taps into "evaluation aspects for a set of one or more health information systems — whether similar or heterogeneous — by organizing, unifying, and aggregating the quality attributes extracted from those systems and from an external evaluation framework." As such, the group developed the UVON method, which they conclude can be used " to create ontologies for evaluation" of health information systems as well as "to mix them with elements from other evaluation frameworks."
Posted on June 14, 2016
By John Jones
Journal articles
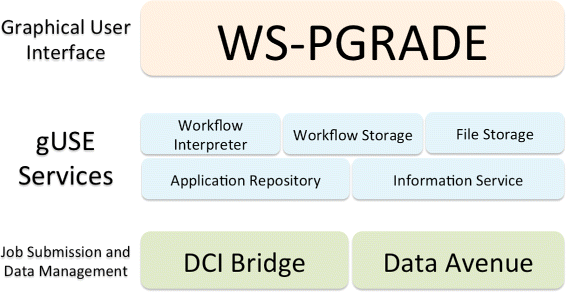
This featured article from the journal
BMC Bioinformatics falls on the heels of several years of discussion on the topic of reproducibility of a scientific experiment's end results. De la Garza
et al. point to workflows and their repeatability as vital cogs in such efforts. "Breaking down the complexity of such experiments into the joint collaboration of small, repeatable, well defined tasks, each with well defined inputs, parameters, and outputs, offers the immediate benefit of identifying bottlenecks, pinpoint sections which could benefit from parallelization," they state. The researchers developed their own set of free platform-independent tools for designing, executing, and sharing workflows. They conclude: "We are confident that our work presented in this document ... not only provides scientists a way to design and test workflows on their desktop computers, but also enables them to use powerful resources to execute their workflows, thus producing scientific results in a timely manner."
Posted on June 7, 2016
By John Jones
Journal articles
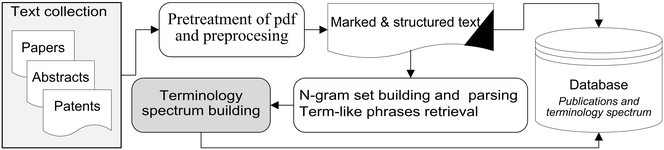
In this 2016 journal article published in
Journal of Cheminformatics, Alperin
et al. present the fruits of their labor in an attempt to " to develop, test and assess a methodology" for both extracting and categorizing words and terminology from chemistry-related PDFs, with the goal of being able to apply "textual analysis across document collections." They conclude that "[t]erminology spectrum retrieval may be used to perform various types of text analysis across document collections" as well as "to find out research trends and new concepts in the subject field by registering changes in terminology usage in the most rapidly developing areas of research."
Posted on June 3, 2016
By John Jones
Journal articles

Digital health services is an expanding force, empowering people to track and manage their health. However, it comes with cost and legal concerns, requiring a legal framework for the development and assessment of those services. In this 2016 paper appearing in
JMIR Medical Informatics, Garrell
et al. lay out such a framework based around Swedish law, though leaving room for the framework to be adapted to other regions of the world. They conclude that their framework "can be used in prospective evaluation of the relationship of a potential health-promoting digital service with the existing laws and regulations" of a particular region.
Posted on May 25, 2016
By John Jones
Journal articles
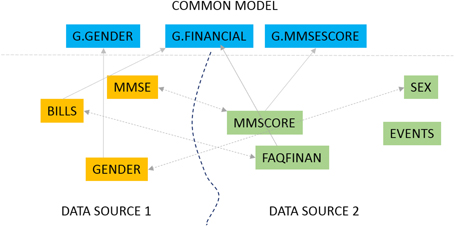
In this 2016 article appearing in
Frontiers in Neuroinformatics, Ashish
et al. present GEM, "an intelligent software assistant for automated data mapping across different datasets or from a dataset to a common data model." Used for Alzheimer research though applicable to many other fields, the group concludes "[o]ur experimental evaluations demonstrate significant mapping accuracy improvements obtained with our approach, particularly by leveraging the detailed information synthesized for data dictionaries."











