Posted on May 7, 2019
By Shawn Douglas
Journal articles
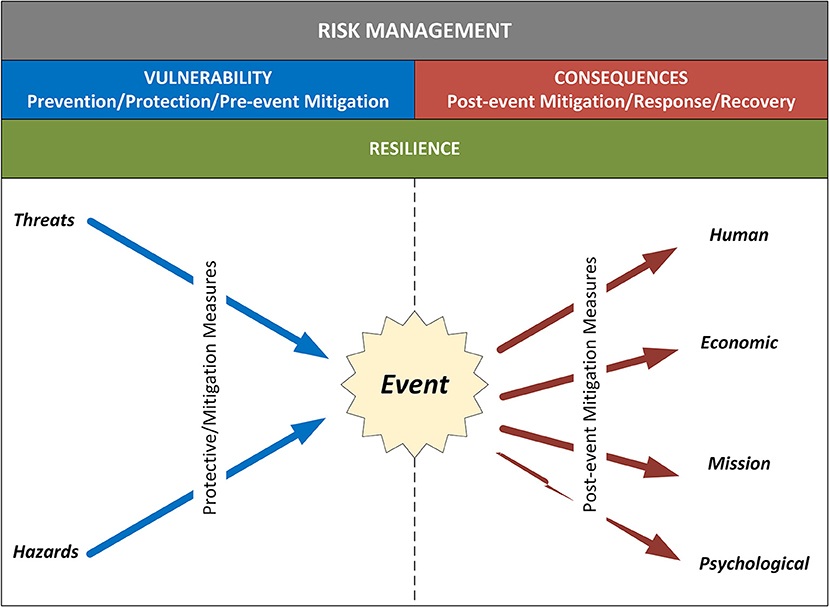
Here is one more journal article on the topic of cyberbiosecurity, this time discussing related vulnerabilities and the need for a resilient infrastructure to limit them. Schabacker
et al. of the Argonne National Laboratory present a base "assessment framework for cyberbiosecurity, accounting for both security and resilience factors in the physical and cyber domains." They first discuss the differences between "emerging" and "converging" technologies and how they contribute to vulnerabilities, and then they lead into risk mitigation strategies. The authors also provide clear definitions of associated terminology for common understanding, including the topics of dependency and interdependency. Then they discuss the basic framework, keeping vulnerabilities in mind. They close with a roadmap for a common vulnerability assessment framework, encouraging the application of "lessons learned from parallel efforts in related fields," and reflection on "the complex multidisciplinary cyberbiosecurity environment."
Posted on April 29, 2019
By Shawn Douglas
Journal articles
From software development companies to pharmaceutical manufacturers, businesses, governments, and non-profit entities alike are beginning to adopt tools meant to improve communication, information sharing, and productivity. In some cases, this takes the form of an enterprise social media platform (ESMP) with chat rooms, discussion boards, and file repositories. But while this can be beneficial, adding a focused attempt at sharing to work culture can create its own share of problems, argues Norwegian University of Science and Technology's Halvdan Haugsbakken, particularly due to varying definitions and expectations of what information "sharing" actually is. Using a case study of regional government in Norway, Haugsbakken found "when the end-users attempted to translate sharing into a manageable practice—as the basis for participation in a knowledge formation process—they interpreted sharing as a complicated work practice, with the larger consequence of producing disengaged users." This result "suggests a continued need for the application of theoretical lenses that emphasize interpretation and practice in the implementation of new digital technologies in organizations."
Posted on April 22, 2019
By Shawn Douglas
Journal articles
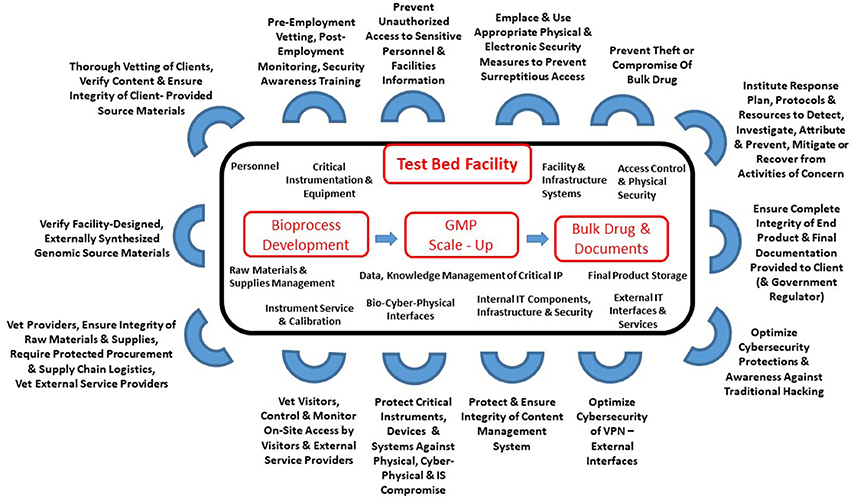
Following up on the cyberbiosecurity article posted a few weeks ago, this one by Murch
et al. steps away from the strong agriculture focus of the prior and examines cyberbiosecurity from a more broad perspective. Not only do the authors provide background into the convergence of cybersecurity, cyber-physical security, and biosecurity, but they also provide a look at how it extends to biomanufacturing facilities. They conclude that cyberbiosecurity could be applied to various domains—from personalized genomics and medical device manufacturing to food production and environmental monitoring— though continued "[d]irect and ordered engagements of the pertinent sectors of the life sciences, biosecurity, and cyber-cybersecurity communities," as well as tangentially within academia and government, must continue to occur in order "to harmonize the emerging enterprise and foster measurable value, success, and sustainability."
Posted on April 15, 2019
By Shawn Douglas
Journal articles
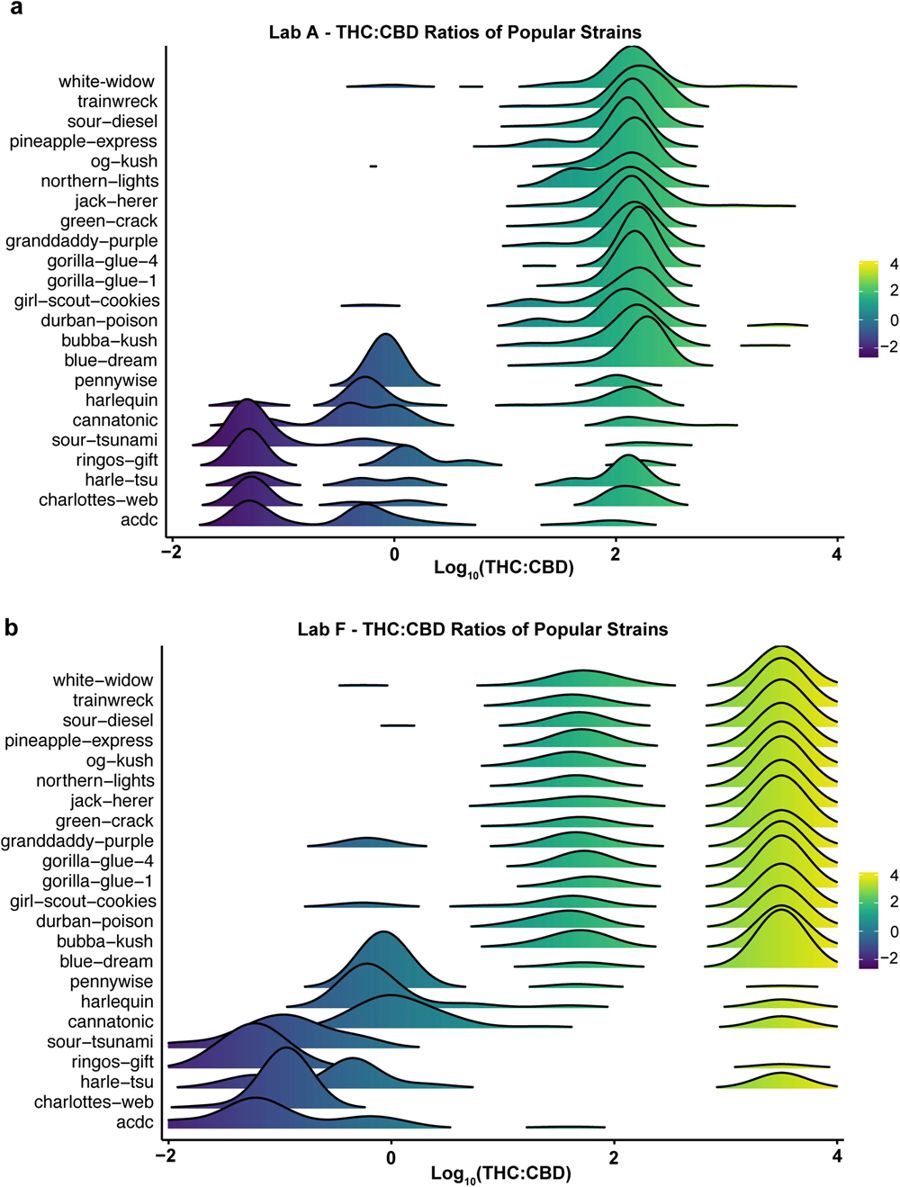
In 2017, Washington State's cannabis testing laboratories were going through a mini-crisis, with questions of credibility being raised about certain laboratories' testing methodologies and practices. How much were differences in tested samples based on differences in methodologies? What more can be done by laboratories in the industry? This 2018 paper by Jikomes and Zoorob answer these questions and more, using "a large dataset from Washington State’s seed-to-sale traceability system." Their analyses of this dataset showed "systematic differences in the results obtained by different testing facilities in Washington," leading to "cannabinoid inflation" in certain labs. The authors conclude that despite the difficulties of having cannabis illegal at the federal level, efforts to standardize testing protocols etc. must continue to be made in order to protect consumers and increase confidence in the testing system.
Posted on April 9, 2019
By Shawn Douglas
Journal articles
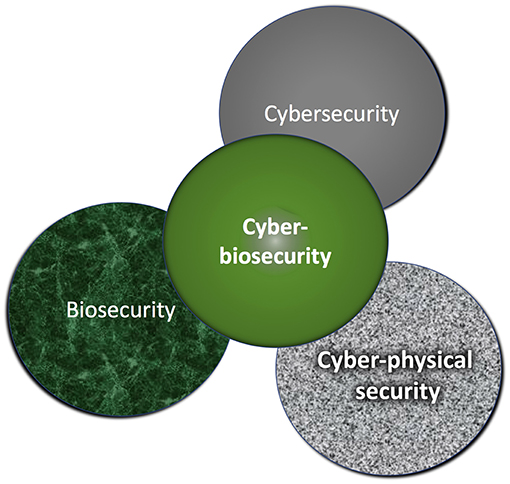
We know that the research process creates data, and data is increasingly valuable. But can we visualize all the nooks and crannies that data is coming from in a more technologically connected society? Take for instance the food and agriculture sectors, influencing more than 20 percent of the U.S. economy. Herd data records for the dairy industry, pedigree information for the food animal industry, and soil and machine condition data from row crop farmers are only a few examples of data sources in the sectors. But what of the security of that data? Duncan
et al. take a brief look at these sectors and provide insight into the ways that cybersecurity, biosecurity, and their intersections are increasingly important. The conclude by making suggestions for "[w]orkforce development, effective communication strategies, and cooperation across sectors and industries" to better "increase support and compliance, reducing the risks and providing increased protection for the U.S. bioeconomy."
Posted on April 2, 2019
By Shawn Douglas
Journal articles
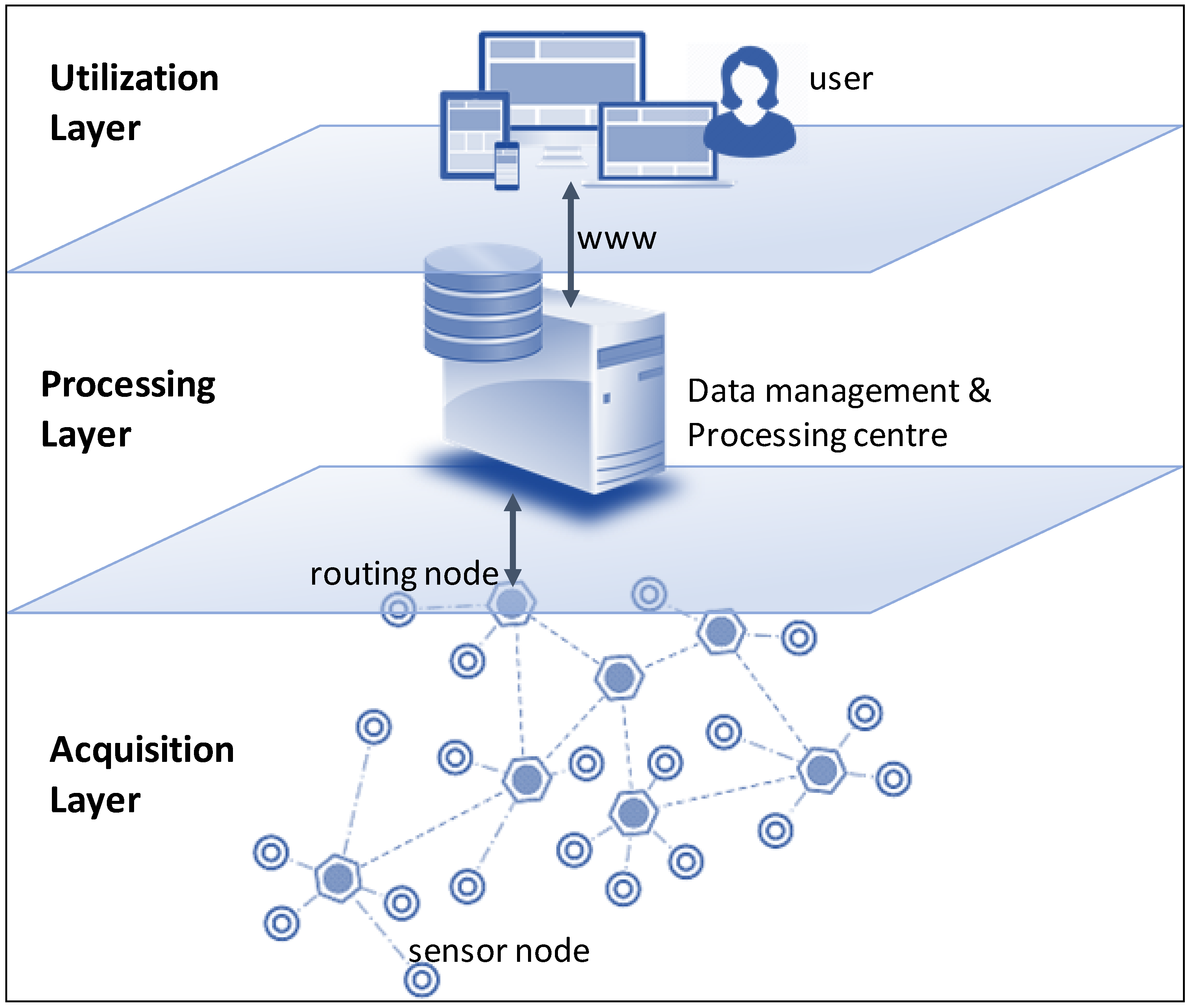
In this 2018 paper published in
Sensors, Perez-Castillo
et al. present DAQUA-MASS, their own take on the ISO 8000-61 data quality standard but updated for the world of the internet of things and smart, connected products (SCPs), in particular sensor networks. While recognizing that data quality has been studied significantly over the decades, little work has gone into the formal policies for SCP and sensor data quality. After presenting data challenges in SCP environments, related work, their model, and their methodology, the authors conclude that their "data quality model, along with the methodology, offers a unique framework to enable designers of IoT projects—including sensor networks and practitioners in charge of exploiting IoT systems—to assure that the business processes working over these systems can manage data with adequate levels of quality."
Posted on March 26, 2019
By Shawn Douglas
Journal articles
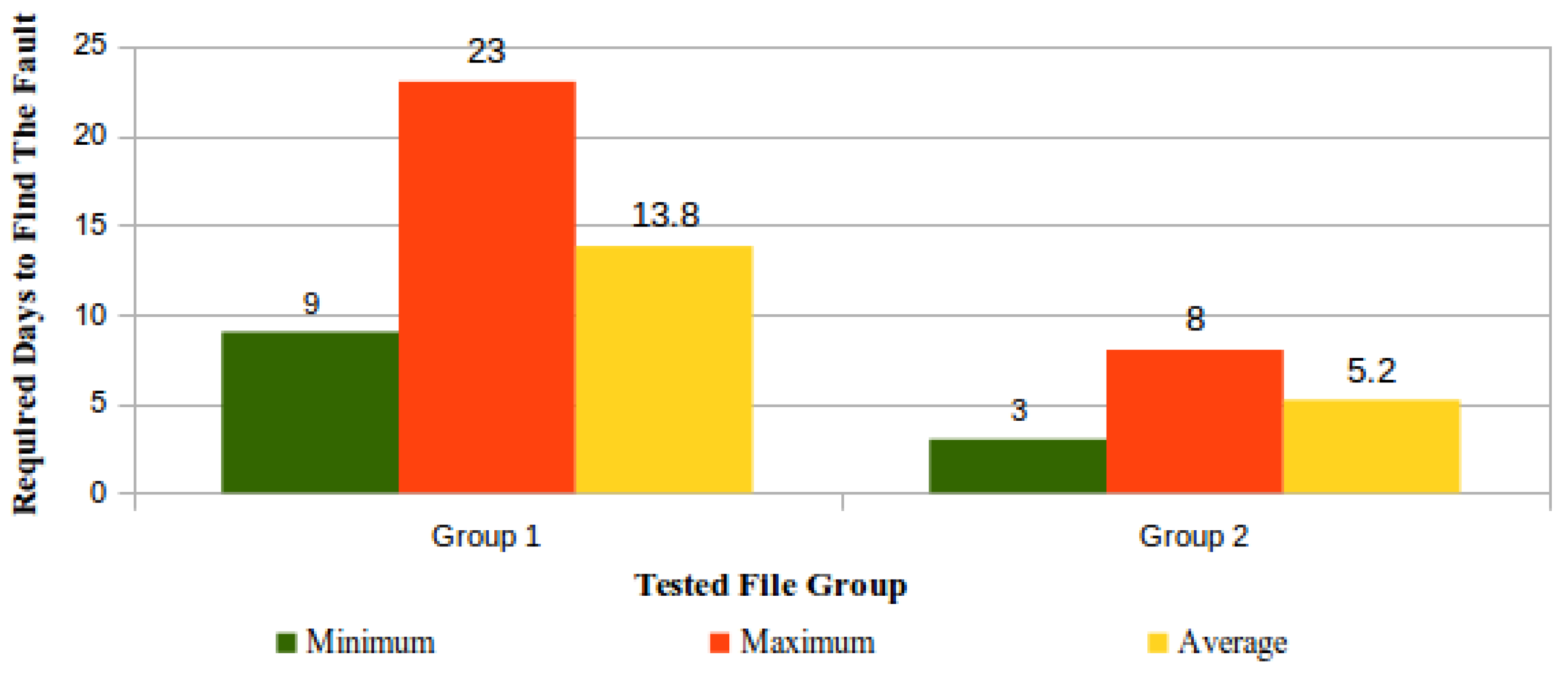
Have you considered the security of your files hosted in the cloud? Of course you have, and reputable providers provide a solid guarantee of safety. But what if you could monitor the status of your files as well as the behavior of your cloud service provider? In this 2018 paper published by Pinheiro
et al., such a proposition is proven as practical. The authors demonstrate just that using architecture that includes a "protocol based on trust and encryption concepts to ensure cloud data integrity without compromising confidentiality and without overloading storage services." They conclude that not only is such monitoring able to be done efficiently and rapidly, but also the "architecture proved to be quite robust during the tests, satisfactorily responding to the fault simulations," including unplanned server shutdown.
Posted on March 18, 2019
By Shawn Douglas
Journal articles
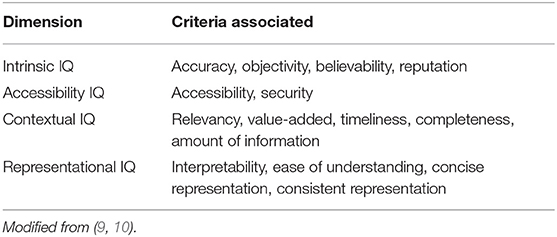
For information technology professionals and informaticists alike, when handling data, the idea of "garbage in, garbage out" remains a popular refrain. Collecting data isn't enough; its quality for future analysis, sharing, and use is also important. Similarly, with the growth of the internet, the amount of health-related information being pumped online increases, but its quality isn't always attended to. In this 2018 paper by Al-Jefri
et al., the topic of online health information quality (IQ) gets addressed in the form of a developed framework "that can be applied to websites and defines which IQ criteria are important for a website to be trustworthy and meet users' expectations." The authors conclude with various observations, including differences in how education, gender, and linguistic background affects users' ability to gauge information quality, and how there seems to be an overall lack of caring about the ethical trustworthiness of online health information by the public at large.
Posted on March 12, 2019
By Shawn Douglas
Journal articles
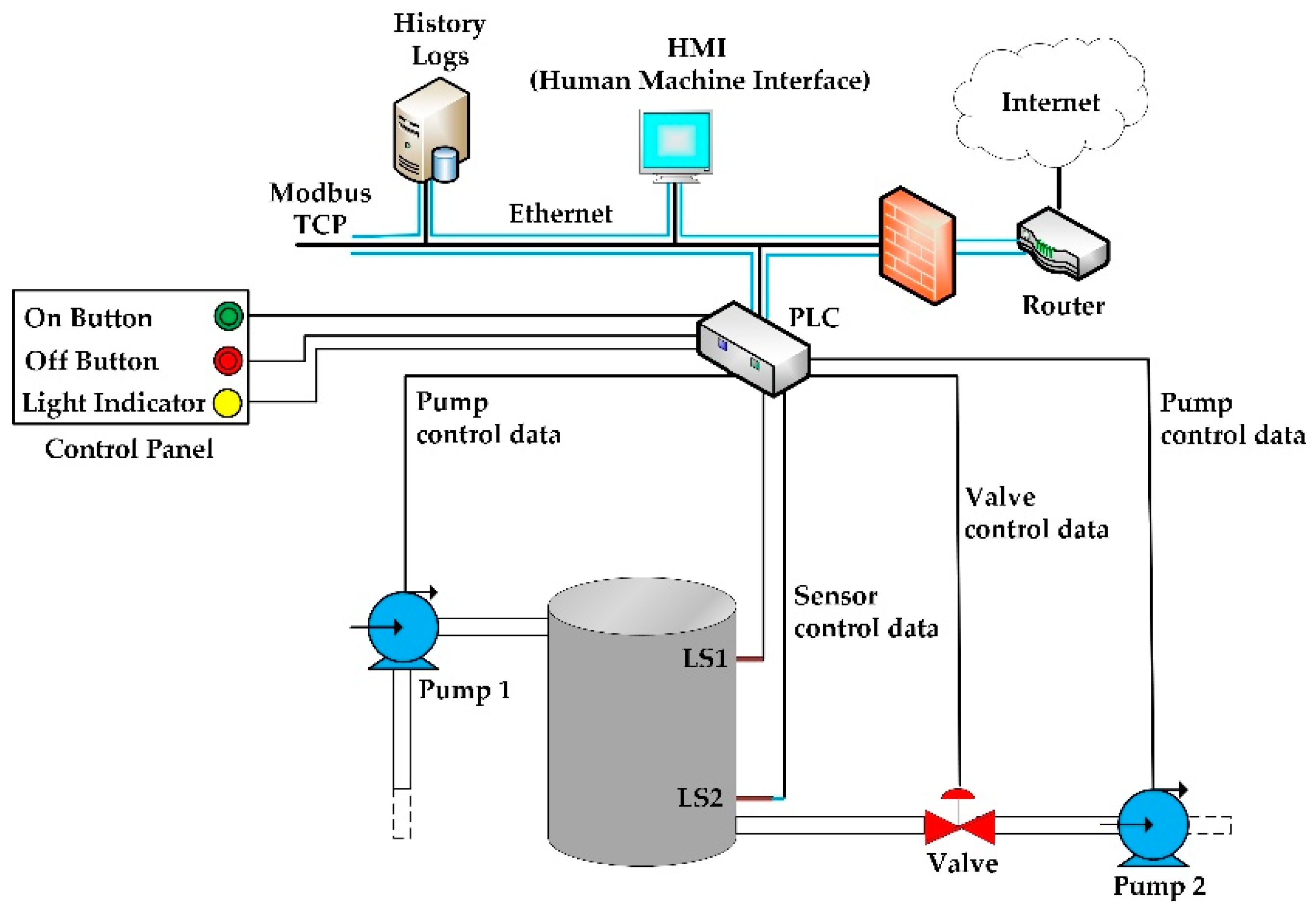
In this 2018 article published in
Future Internet, Teixeira
et al. test five machine learning algorithms in a supervisory control and data acquisition (SCADA) system testbed to determine whether or not machine learning is useful in cybersecurity research. Given the increasing number and sophistication of network-based attacks on industrial and research sensor networks (among others), the authors assessed the prior research of others in the field and integrated their findings into their own SCADA testbed dedicated to controlling a water storage tank. After training the algorithms and testing the system with attacks, they concluded that the Random Forest and Decision Tree algorithms were best suited for the task, showing " the feasibility of detecting reconnaissance attacks in [industrial control system] environments."
Posted on March 6, 2019
By Shawn Douglas
Journal articles
The field of bioinformatics has really taken off over the past decade, and so with it has the number of data sources and the need for improved visualization tools, including in the realm of three-dimensional visualization of molecular data. As such, Trellet
et al. have developed the infrastructure for "an integrated pipeline especially designed for immersive environments, promoting direct interactions on semantically linked 2D and 3D heterogeneous data, displayed in a common working space." The group discusses in detail bioinformatics ontologies and semantic representation of bioinformatics knowledge, as well as vocal-based query management with such a detailed system. They conclude their efforts towards their "pipeline might be a solid base for immersive analytics studies applied to structural biology," including the ability to propose "contextualized analysis choices to the user" during interactive sessions.
Posted on February 26, 2019
By Shawn Douglas
Journal articles
From bioinformatics applications to social media research, the volume and velocity of data to manage continues to grow. Analysis of this massive faucet of data requires new ways of thinking, including new software, hardware, and programming tools. In this 2019 paper published in
Journal of Cloud Computing, Domenico Talia of the University of Calabria in Italy presents a detailed look at exascale computing systems as a way to manage and analyze this river of data, including the use of cloud computing platforms and exascale programming systems. After a thorough discussion, the author concludes that while "[c]loud-based solutions for big data analysis tools and systems are in an advanced phase both on the research and the commercial sides," more work remains in the form of finding solutions to a number of design challenges, including on the data mining side of algorithms.
Posted on February 18, 2019
By Shawn Douglas
Journal articles

We go back in time a year for this brief paper published by Swaminathan
et al. of Nationwide Children's Hospital in Ohio. The researchers present their experiences handling the nuances of transferring large genomic data files of individual patients to a sequencing lab, all while handling the security and privacy protections surrounding the data. Handling only 19 patients' genomic files, at least initially, presented a number of workflow and protocol challenges for both hospital and laboratory. They conclude with barriers (file size and workflow management consistency) and suggestions (EHR-based alerts, blockchain) about what could be improved with such data transfers in the future to better realize the "massive potential to leverage genomic data to advance human health overall."
Posted on February 12, 2019
By Shawn Douglas
Journal articles
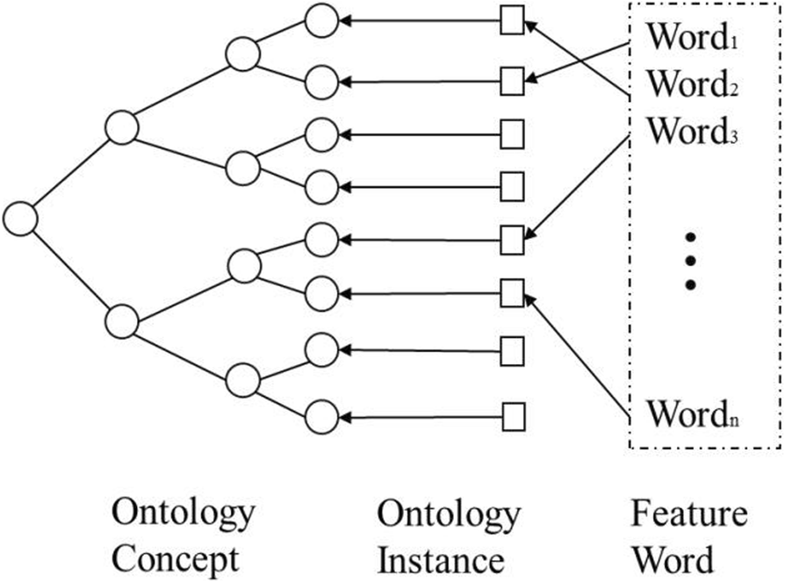
Whether it's a document management system or a laboratory information management system, some sort of query function is involved to help the user find specific documents or data. How that data is retrieved—using information retrieval methods—can vary, however. In this 2019 paper published in
EURASIP Journal on Wireless Communications and Networking, Binbin Yu details a modified information retrieval methodology that uses a domain-ontology-based approach that integrates document processing and retrieval aspects of the query. Domain ontology takes into account semantic information and keywords, which improves recall and precision of results. After explaining the mathematics and experimentation methodology, Yu concludes "the genetic algorithm shortens the distance compared with simulated annealing, and the ontology retrieval model exhibits a better precision and recall rate to understand the users’ requirements."
Posted on February 5, 2019
By Shawn Douglas
Journal articles
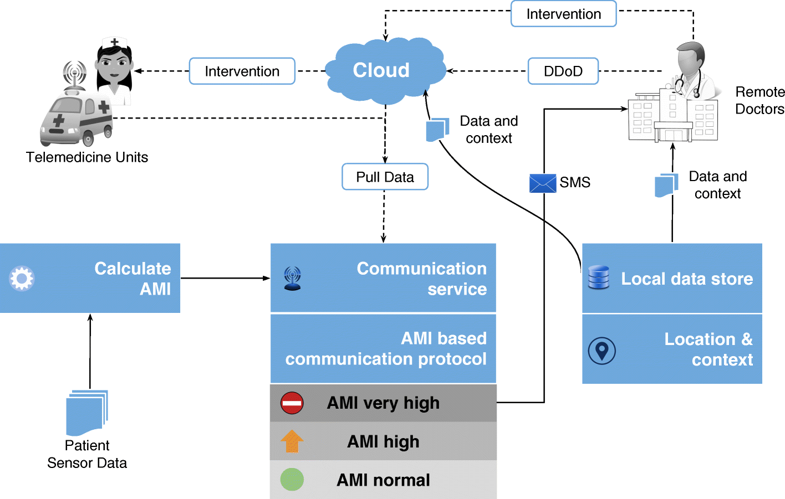
In this late 2018 paper published in
BMC Medical Informatics and Decision Making, Pathinarupothi
et al. with the Amrita Institute of Medical Sciences present their Rapid Active Summarization for Effective Prognosis (RASPRO) framework for healthcare facilities. Noting an increasing volume of data coming from body-attached senors and a lack of making the best sense of it, the researchers developed RASPRO to provide summarized patient/disease-specific trends via body sensor data and aid physicians in being proactive in more rapidly identifying the onset of critical conditions. This is done through the implementation of "physician assist filters" or PAFs, which also enable succinctness and decision making even over bandwidth-limited communication networks. They conclude the system "helps in personalized, precision, and preventive diagnosis of the patients" while also providing the benefits of availability, accessibility, and affordability for healthcare systems.
Posted on January 28, 2019
By Shawn Douglas
Journal articles
What do you do when your newborn screening program grows in importance, beyond its original data management origins in a time of cloud computing and integrated informatics systems for healthcare? Entities such as Newborn Screening Ontario (NSO) have risen to the challenges inherent to this question, undertaking an end-to-end assessment of their needs and existing capabilities, in the process deciding on "a holistic full product lifecycle redesign approach." This paper describes the full process as conducted by NSO, from theory to practice. The authors conclude "that developing, implementing, and deploying a [screening information management system] is about much more than the technology; team engagement, strong leadership, and clear vision and strategy can lead newborn screening programs looking to do the same to success and long-term gains in patient outcomes.
Posted on January 21, 2019
By Shawn Douglas
Journal articles
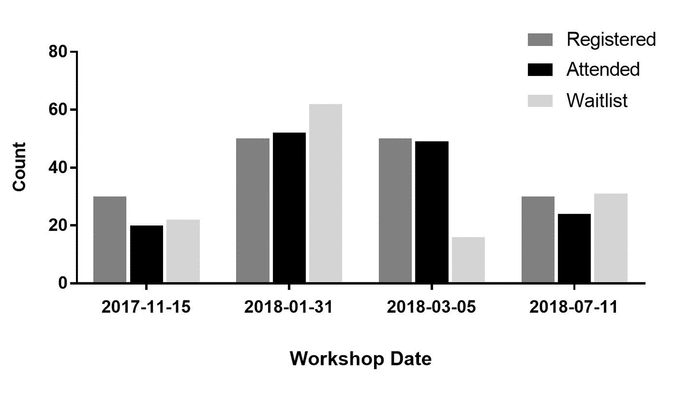
In this 2019 paper written by New York University School of Medicine's Kevin B. Read, the topic of clinical research data management (CRDM) is discussed, particularly in its application at the NYU Health Sciences Library. Identifying a strong need by the clinical research community at the university for CRDM training, Read—acting as the Data Services Librarian and Data Discovery Lead—developed curriculum to support such a mission and offered training. This article details his journey as such, ending with supporting data and a strong feeling that the end result is a "research community being better trained, more compliant, and increasingly aware of established institutional workflows for clinical research."
Posted on January 14, 2019
By Shawn Douglas
Journal articles
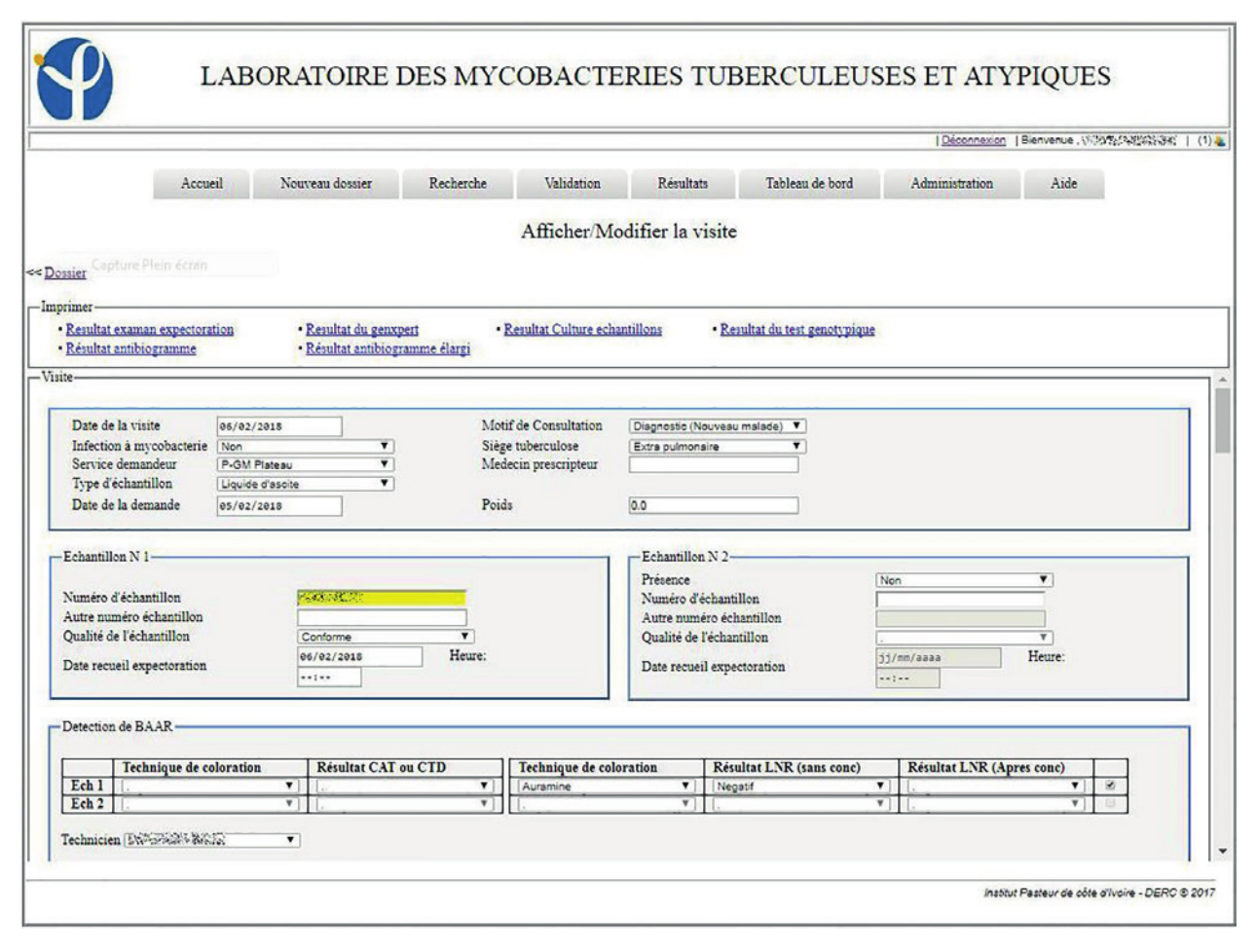
In this 2019 paper, Koné
et al. of the Pasteur Institute of Côte d’Ivoire provide insight into their self-developed laboratory information system (LIS) specifically designed to meet the needs of clinicians treating patients infected with
Mycobacterium tuberculosis. After discussing its design, architecture, installation, training sessions, and assessment, the group describes system launch and how its laboratorians perceived the change from paper to digital. With some discussion, they conclude they have improved, more real-time "indicators on the follow-up of samples, the activity carried out in the laboratory, and the state of resistance to antituberculosis treatments" with the conversion.
Posted on January 7, 2019
By Shawn Douglas
Journal articles
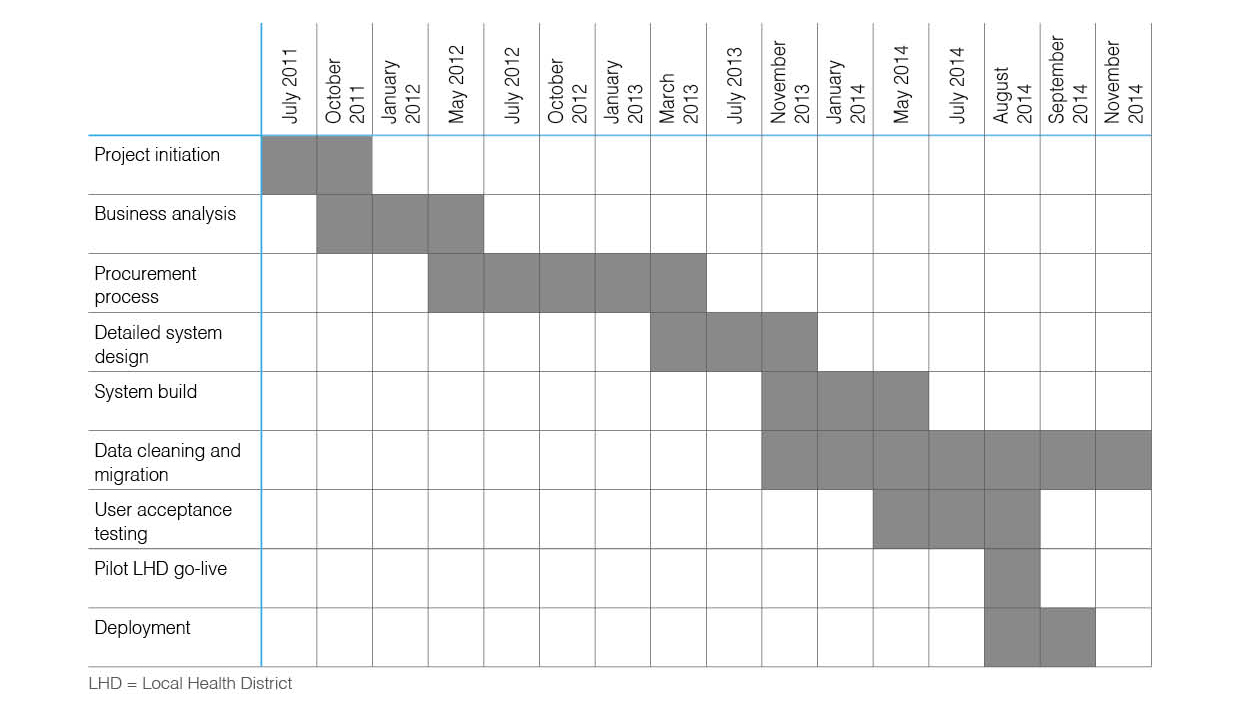
Attempting to implement a regional public health initiative affecting thousands of children is daunting enough, but collecting, analyzing, and reporting critical data that shows efficacy can be even more challenging. This 2018 article published in
Public Health Research & Practice demonstrates one approach to such an endeavor in New South Wales Australia. Green
et al. discuss the design and implementation of their Population Health Information Management System (PHIMS) to integrate and act upon data associated with not one but two related public health programs targeting the prevention of childhood obesity. The article also discusses some of the challenges with the project, from funding and training all 15 New South Wales local health districts to ensuring support across all the districts for consistent operation and security despite differing IT infrastructures. They conclude that despite the challenges, their award-winning PHIMS solution has been vital to the two programs' success.
Posted on December 18, 2018
By Shawn Douglas
Journal articles
In this brief paper published in
Folia Forestalia Polonica, Series A – Forestry, Dorota Grygoruk of Poland's Forest Research Institute presents the development of the open data concept within the context of Poland and other countries, while also addressing how data sharing and management is challenged by the paradigm. Grygoruk first defines the open data and open access concepts and then describes how policy in Poland and the European Union has been adopted to specify those concepts within institutions. The author then analyzes the challenges of implementing data sharing inherent to research data management, including within the context of forestry informatics. The conclusion? The "organizational and technological solutions that enable analysis" are increasingly vital, and " it becomes necessary for research institutions to implement data management policies," including data sharing policies.
Posted on December 11, 2018
By Shawn Douglas
Journal articles
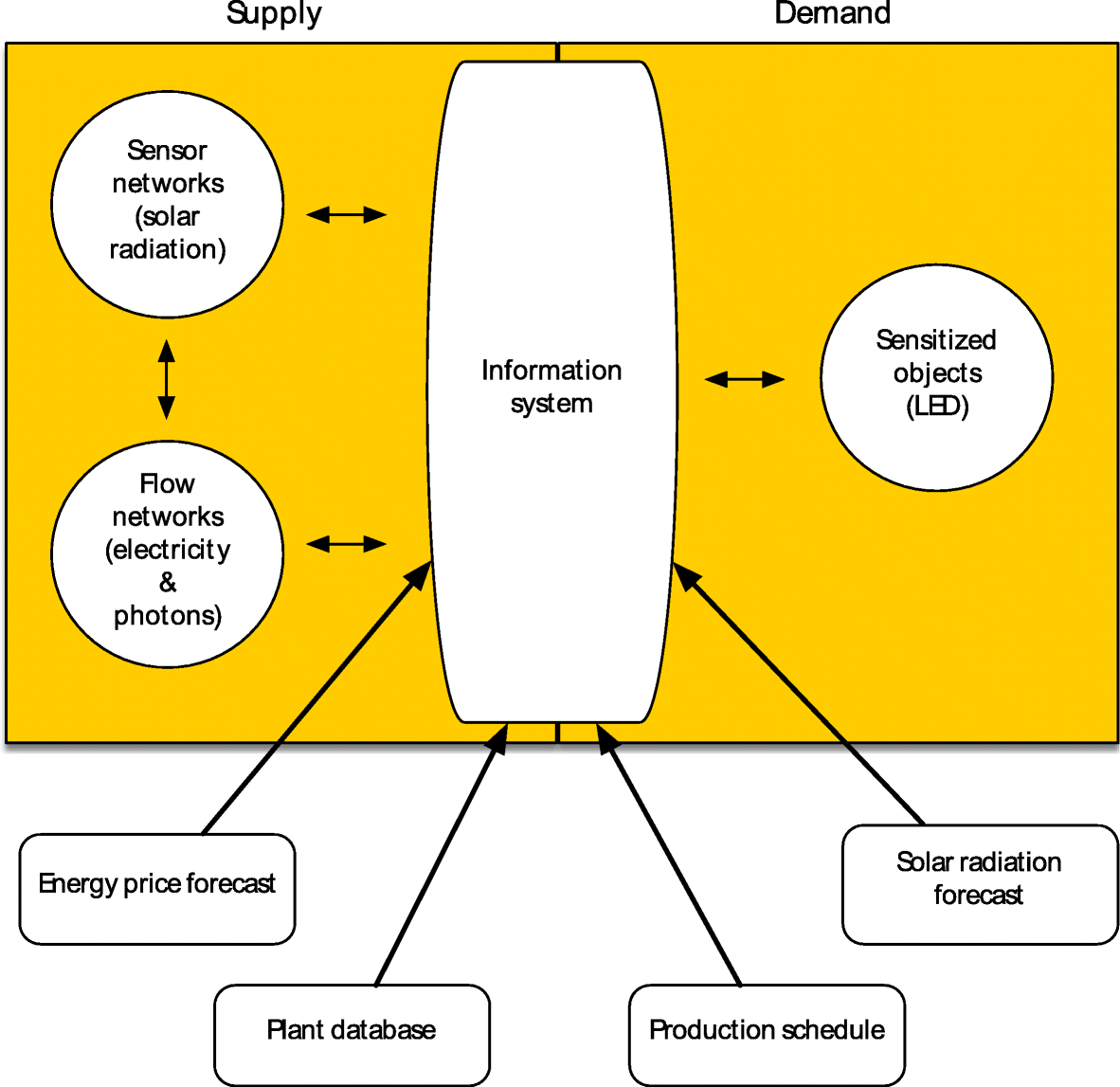
In the inaugural issue of the journal
Energy Informatics, Watson
et al. of the University of Georgia - Athens provide research and insight into how databases, data streams, and schedulers can be joined with an information system to drive more cost-effective energy production for greenhouses. Combining past research and new technologies, the authors turn their sights to food security and the importance of developing more efficient systems for greater sustainability. They conclude that an energy informatics framework applied to controlled-environment agriculture can significantly reduce energy usage for lighting, though "engaging growers will be critical to adoption of information-systems-augmented adaptive lighting."














